Model de Keras
Dans ce billet, nous allons voir comment créer un model de Keras pour l'apprentissage profond. D'abord, nous allons voir l'exemple de MNIST de Keras d'ici.
Le code du fichier est comme ça:
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
batch_size = 128
num_classes = 10
epochs = 20
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Le model du fichier est créé comme :
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
La fonction de "Dense"
En fait, la fonction de "Dropout" est utilisé pour le donner imprévisibilité et pour empêcher l'apprentissage profond de faire mémoriser les données. Alors ce code fonctionne aussi.
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dense(512, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
Alors, ce qui compte le plus est la fonction de "Dense". Selon le documentation de Keras, les arguments de la fonction sont comme ça:
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
Le nombre d'abord "512" est "units" du couche. Vous pouvez voir ce site web pour apprendre le "units". C'est le nombre de "output shape".

Illustration 1
Si nous écrivons 512 pour le "units" du couche, le résultat du couche est porté au couche prochain (ce qui a "input shape" de 512). Alors le nombre est un "output shape" du couche.
Mais pourquoi 512? En fait, nous ne sommes pas pourquoi. Peut-être l'apprentissage profond a besoin d'utiliser 512 neurones pour classer les tous dispositions. Nous devons trouver le meilleur nombre par tâtonnements.
Video 1 (anglais)
Le couche dernier a "num_classes" (= 10) pour "units" parce que le couche dernier sortir un nombre des 0 - 9 (0, 1, 2, 3 ... 9. 10 nombres).
"input_shape" de la fonction de "Dense"
Seulement le couche premier a "input_shape", ce qui est utilisé pour spécifier quel "shape" est utiliser pour le couche premier. Nous ne devons pas spécifier le "input_shape" pour les couches après le premier parce que le code peut savoir le nombre de "input shape" par le nombre de "output shape" du couche précédent.
Les échantillons de MNIST sont les images des nombres écrit à la main. Chaque image a 28 * 28 (=784) pixels avec l'échelle des gris comme ça:
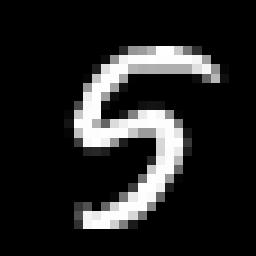
Nous passons les donnes des 784 pixels à le couche premier, alors le couche premier doit avoir "784" pour le "input_shape".
La conclusion
Comme nous avons vu au-dessus, le model de Keras est créé comme ça:
model = Sequential()
// 28 * 28 pixels = 784 pixel
// 512 pour le "output shape".
model.add(Dense(512, activation='relu', input_shape=(784,)))
// 512 pour le "output shape".
model.add(Dense(512, activation='relu'))
// 0, 1, 2, 3 ... Le code va choisir un nombre de 10 nombres.
model.add(Dense(10, activation='softmax'))
Mais le model de Keras peut-être créé comme ça aussi pour le MNIST:
Ce code fonctionne.
Et nous pouvons créer le model comme ça aussi si nous voulons:
model = Sequential()
model.add(Dense(300, activation='relu', input_shape=(784,)))
model.add(Dense(300, activation='relu'))
model.add(Dense(300, activation='relu'))
model.add(Dense(300, activation='relu')) // Trois couches cachés!
// 0, 1, 2, 3 ... Le code va choisir un nombre de 10 nombres.
model.add(Dense(10, activation='softmax'))Et nous pouvons créer le model comme ça aussi si nous voulons:
model = Sequential()
model.add(Dense(1, activation='relu', input_shape=(784,)))
model.add(Dense(1, activation='relu'))
model.add(Dense(1, activation='relu'))
model.add(Dense(1, activation='relu'))
model.add(Dense(1, activation='relu')) // Quatre couches cachés avec 1 neurone!
model.add(Dense(10, activation='softmax'))